Konfiguration aus einer CF-Datei installieren. Grundlegende Informationen Löschen der Infobase von Daten
In früheren Lektionen haben wir erwähnt, dass die Konfiguration aus einer Datei mit der Erweiterung .CF importiert werden kann. Beispielsweise kann Ihnen ein befreundetes Unternehmen eine solche Datei zur Verfügung stellen, damit Sie die neueste Version der Konfiguration installieren und damit experimentieren können. Bei einer solchen Entwicklung der Ereignisse müssen Sie wie folgt vorgehen.
Klicken Sie zunächst in dem Ihnen bereits bekannten Fenster, das nach dem Start des Programms erscheint, auf die Schaltfläche Hinzufügen.
Wählen Sie im nächsten Fenster aus Schaffung einer neuen Informationsbasis.
Im nächsten Fenster müssen Sie den Punkt „Infobase ohne Konfiguration erstellen“ auswählen, um eine neue Konfiguration zu entwickeln oder eine zuvor entladene Infobase zu laden.
Geben Sie im nächsten Fenster den Namen der Datenbank an.
Nach Abschluss der in der Liste aufgeführten Aktionen Informationsbasen Es erscheint eine neue leere Datenbank. Jetzt müssen Sie es auswählen und auf die Schaltfläche Konfigurator klicken. Das Konfiguratorfenster öffnet sich.
Wenn Sie das Fenster zum ersten Mal öffnen, ist es leer und jetzt müssen wir einige Schritte ausführen, um die CF-Datei, die Sie haben, in die leere Konfiguration zu laden.
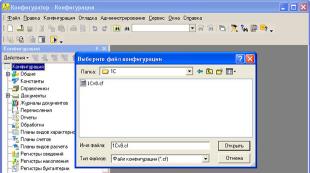
Menübefehl ausführen Konfiguration > Konfiguration öffnen. Das Programmfenster ändert sich – im linken Teil öffnet sich der Konfigurationsbaum. Es interessiert uns noch nicht. Jetzt können Sie den Befehl ausführen Konfiguration > Konfiguration aus Datei laden. Mit diesem Befehl können Sie die vorhandene (in unserem Fall leere) Konfiguration vollständig durch die in der CF-Datei gespeicherte Konfiguration ersetzen. Im erscheinenden Fenster müssen Sie den Pfad zu der Datei angeben, in der die Konfiguration, die Sie laden möchten, gespeichert ist.

Jetzt müssen Sie nur noch einen Knopf drücken Offen und warten Sie, bis das Programm die Konfiguration lädt. Dies kann recht lange dauern. Wenn das System Ihnen Fragen stellt (insbesondere zum Aktualisieren der Datenbankkonfiguration, zum Akzeptieren von Änderungen in der Struktur der Konfigurationsinformationen), beantworten Sie diese mit Ja.
In der unteren linken Ecke des Programmfensters werden Servicemeldungen über den Fortschritt des Konfigurationsupdates angezeigt. Nachdem das Update abgeschlossen ist (Dienstmeldungen zum Laden der Datenbank werden gestoppt), können Sie das Konfiguratorfenster schließen und das Programm im Benutzermodus ausführen. Allerdings ist in der Praxis die Installation Informationsbasis Die Verwendung einer der oben genannten Methoden schränkt in der Regel nicht die Dinge ein, die vor der ersten Ausführung der Konfiguration erledigt werden müssen. Insbesondere dürfen wir Updates nicht vergessen.
Der interne Aufbau der Konfigurationsdatei (*.cf) ist schon lange kein Geheimnis mehr, es gibt aber praktisch keine ausführliche Dokumentation dazu im Internet. Dieser Artikel ist ein Versuch, diese Lücke zu schließen.
Der interne Aufbau der Konfigurationsdatei (*.cf) ist kein Geheimnis. Gute Leute haben es vor langer Zeit auseinandergenommen und viele interessante Dienstprogramme erstellt, die es Ihnen ermöglichen, mit diesem Format zu arbeiten. Auf Infostart gibt es ein gutes Dutzend (wenn nicht mehr) interessante Veröffentlichungen, die auf die eine oder andere Weise den Inhalt von *.cf-Dateien lesen, daher ist dieses Thema überhaupt nicht neu.
Allerdings gibt es für dieses Format leider nur sehr wenige gute und qualitativ hochwertige Dokumentationen. Inspiriert wurde ich zum Schreiben dieses Artikels durch die Veröffentlichung des angesehenen awa, der die Struktur des 1C:Enterprise-Dat(*.1CD) ausführlich beschrieb.
Meiner Meinung nach wurde dieser Artikel zum Katalysator für eine Reihe von Entwicklungen anderer Autoren. Die Offenheit und Zugänglichkeit der Informationen regte die kreative Aktivität der Autoren an und die gesamte Community erhielt eine Reihe hervorragender Tools für die Arbeit mit 1C-Dateidatenbanken.
Mir scheint, dass eine detaillierte Beschreibung des CF-Formats auch für viele Autoren von Interesse sein wird und wir vielleicht die Gelegenheit bekommen, viele neue interessante Entwicklungen zum Thema Konfigurationsdateien zu sehen.
Hintergrund
Wie oben erwähnt, ist die Struktur des Formats seit langem bekannt und es gibt (wenn auch eher dürftige) Informationen zu seiner Struktur im Internet. Ich brauchte diese Informationen bei der Entwicklung des V8Viewer-Programms, bei dessen Arbeit ich mich auf die folgenden Materialien stützte:
Terminologie
Kommen wir direkt zum Thema unserer Diskussion.
Um das Ganze abzurunden, entscheiden wir uns für den Namen des Formats selbst.
Zum einen werden in diesem Format nicht nur Konfigurationsdateien erstellt, sondern auch externe Reporting- und Verarbeitungsdateien. Im Internet bin ich auf den Namen Compound-Datei gestoßen. Vielleicht ist es unter 1C-Oldtimern gut etabliert, aber mir gefällt es nicht wirklich.
Für die Zwecke dieses Artikels schlage ich vor, dieses Format als „Container“ zu bezeichnen. Wenn das liebe Publikum in den Kommentaren den richtigen Namen vorschlägt, freue ich mich sehr.
Schauen wir hinein
Die logische Einheit der Datenspeicherung innerhalb eines Containers ist ein Dokument. Ein Dokument ist ein aussagekräftiger, vollständiger Datensatz, der auf irgendeine Weise gelesen und interpretiert werden kann. Den Begriff „Datei“ verwende ich ausdrücklich nicht, da ich diesen Namen einer anderen Entität vorbehalte, auf die ich etwas später eingehen werde.
Im Allgemeinen ist eine CF-Datei (EPF/ERF) ein Container, in dem Dokumente gespeichert werden.
Jedes Dokument in einem Container kann in Blöcke unterteilt werden. Die minimale physische Einheit der Datenspeicherung ist ein Block, die sinnvolle logische Einheit ist jedoch ein Dokument. Mit anderen Worten: Dokumente in einem Container können in Form verstreuter Teile (Blöcke) liegen und um den Inhalt des Dokuments lesen zu können, müssen alle Teile gesammelt und kombiniert werden.
Containerstruktur
Der Behälter enthält die folgenden Teile (in der Reihenfolge):
Container-Header Adresse des ersten leeren Blocks, in den Daten eingefügt werden können Standardblockgröße Anzahl der Dateien im Container Container-Inhaltsverzeichnisdokument Die tatsächlichen Daten, die im Inhaltsverzeichnis aufgeführt sind
Blockstruktur
Ein Block besteht aus einem Header und einem Body. Der Header gibt die Gesamtgröße des gesamten Dokuments, die Größe des aktuellen Blocks und die Adresse (Position in der Datei) des nächsten Blocks an. Unmittelbar nach dem Header folgt der Hauptteil des Blocks – also die Daten, die wir benötigen. Der Blockkörper hat genau die im Header angegebene Länge (in Bytes).
Im Inneren des Containers gibt es hier und da eine magische Konstante, die eine gewisse „Leere“ bezeichnet – das ist die Zahl 0x7fffffff.
Wenn wir ein Dokument aus Blöcken zusammensetzen, schauen wir in der Kopfzeile nach der Adresse des nächsten Blocks. Wenn es 0x7fffffff ist, dann gibt es keinen „nächsten“ Block, dieser ist der letzte.
Die Konstante 0x7fffffff ist der Wert von INT_MAX, d.h. der Maximalwert einer 4-Byte-Ganzzahl mit Vorzeichen.
Logische „Dateien“
Ich erwähnte, dass ich mir den Begriff „Datei“ für bessere Zeiten aufheben würde. Diese Zeiten sind gekommen :)
Die gesamte Konfiguration wird als Dateien im Container gespeichert. Wenn wir uns an unseren Informatikkurs erinnern, werden wir uns daran erinnern, dass eine „Datei“, wie uns gesagt wurde, ein benanntes Dokument ist.
Eine Datei unterscheidet sich von einem „Dokument“ dadurch, dass sie einen Namen hat und mit diesem Namen angesprochen werden kann. Wenn wir den Inhalt der Konfiguration analysieren und Metadaten erstellen, werden wir in den Dateien viele Verweise auf andere Dateien finden. Der Konfigurationslesevorgang arbeitet mit Dateinamen und verweist namentlich auf sie.
Zusammenfassend können wir Folgendes sagen: Der Container enthält verschiedene Dokumente, einige davon haben jedoch einen Namen. Solche Dokumente werden „Akten“ genannt und haben keinen Dienstleistungscharakter, sondern unmittelbar anwendbaren Charakter. Es sind die Dateien, die Informationen über Konfigurationsmetadaten speichern.
Dateikomponenten
Jede Datei besteht aus zwei Dokumenten:
Attributdokument, das den Dateinamen und Erstellungs-/Änderungsdaten enthält. Inhaltsdokument, das den eigentlichen Dateikörper enthält. Inhalt des Containers
Nachdem nun alle Komponenten bekannt gegeben wurden, muss noch das vielleicht wichtigste Dokument des Containers betrachtet werden – das Inhaltsverzeichnisdokument, das den Speicherort aller Containerdateien angibt. Wie oben erwähnt, ist das Inhaltsverzeichnisdokument das allererste Dokument des Containers und steht unmittelbar nach dem Containertitel.
Adresse (Datei-Offset) des Attributdokuments Adresse (Datei-Offset) des Inhaltsdokuments Nummer 0x7fffffff (End-of-Record-Markierung).
Ich möchte Sie daran erinnern, dass jedes Dokument in Blöcke unterteilt (fragmentiert) werden kann. Der Algorithmus zum Zusammenstellen eines Dokuments aus Blöcken wird im Folgenden erläutert.
Der Eintrag im Inhaltsverzeichnis ist eine zweistellige Zahl INT32. Die erste Zahl ist die Adresse des Dateiattributdokuments. Diese Adresse führt uns zum Anfang des 1. Blocks des Attributdokuments. Aus dem Attributdokument können wir den Dateinamen herausfinden. Die zweite Zahl ist die Dokumentadresse des Dateiinhalts. Unter dieser Adresse gelangen wir zum Anfang des 1. Blocks des Inhaltsdokuments, von wo aus wir die Dateidaten direkt lesen.
Merkmale der Datenkomprimierung.
Ein Container kann eine Vielzahl von Dateien enthalten. In der Regel handelt es sich hierbei um UTF-8-kodierte Textdateien. Unter den Containerdateien können sich jedoch auch andere Containerdateien befinden. Die einfachste Analogie ist ein Dateisystem. Ein Container ist und die darin enthaltenen Dateien sind sein Inhalt. Ein Verzeichnis kann andere Verzeichnisse enthalten.
Das Stammverzeichnis dieses „Dateisystems“ ist die *.CF-Datei selbst. Darin können sich andere Containerdateien befinden, im Wesentlichen verschachtelte Verzeichnisse, die mit genau demselben Algorithmus gelesen werden und genau dieselbe Struktur haben.
Allerdings gibt es eine Besonderheit des Stammverzeichnisses. Alle Dokumentinhalte von Dateien im Stammverzeichnis werden mithilfe des Deflate-Algorithmus komprimiert. Der Inhalt von Dateien in verschachtelten Verzeichnissen wird nicht mehr komprimiert. Einfach ausgedrückt werden auf der obersten Ebene einer Containerdatei die Körper aller Dateien komprimiert. Wenn die Datei im Container jedoch selbst ein Container ist, werden die darin enthaltenen Dateien bereits in ihrer reinen Form (ohne Komprimierung) geschrieben.
Kette freier Blöcke
Durch das Löschen von Daten aus einem Container können darin Leerzeichen entstehen. Diese Freiräume sind in einer Kette verknüpft und bilden eine Art „Dokument“, dessen Daten fehlen. Mit anderen Worten: Freie Blöcke werden nach demselben Prinzip miteinander verbunden, nach dem Dokumentblöcke miteinander verbunden sind. Die Adresse des ersten freien Blocks wird ganz am Anfang des Container-Headers angegeben. Wenn die Adresse eines freien Blocks INT_MAX ist, bedeutet dies, dass sich in der Mitte des Containers keine freien (leeren) Blöcke befinden.
Kurze Zusammenfassung des theoretischen Teils Die CF(EPF/ERF)-Datei wird im „Container“-Format geschrieben Der Container beginnt mit einem Header Alle Inhalte des Containers, mit Ausnahme des Headers, werden in Form von „Dokumenten“ geschrieben Das Dokument kann in Blöcke unterteilt werden. Das Dokument beginnt mit der Blocküberschrift, anhand derer Sie herausfinden können, wie das gesamte Dokument gelesen werden kann. Unmittelbar nach dem Containertitel befindet sich ein Inhaltsverzeichnis Diese verweisen auf die „Dateien“ innerhalb des Containers. Jede Datei besteht aus zwei Dokumenten – einem Attributdokument, in dem der Name dieser Datei angegeben wird, und einem Inhaltsdokument, in dem sich tatsächlich die Dateidaten befinden. Jeder Inhaltsverzeichniseintrag enthält 2 Adressen. Das erste ist die Adresse des Dateiattributdokuments, das zweite ist die Adresse des Inhaltsdokuments. Ein Container kann verschachtelte Container enthalten (z. B. verschachtelte Ordner). Dateien im Stammcontainer werden mit dem Deflate-Algorithmus komprimiert, Dateien in verschachtelten Containern werden ohne Komprimierung geschrieben. Lassen Sie uns die Bytes schon spüren
Es ist also an der Zeit, darüber nachzudenken, wie genau alle oben genannten Einheiten strukturiert sind.
Die Hauptmethode zum Lesen von Daten aus einem Container besteht darin, die Blockkette zu lesen, aus der bestimmte Dokumente bestehen. Es scheint eine gute Idee zu sein, mit dem Prinzip des Lesens von Blockdokumenten zu beginnen.
Ein Dokument in Blöcken lesen
Jedes Dokument in einem Container muss mit einem Blockheader beginnen. In diesem Fall kann das Dokument in mehrere Blöcke unterteilt werden. Um ein Dokument lesen zu können, müssen Sie es aus Blöcken „zusammensetzen“.
Der Blockheader ist also eine 31 Byte lange Zeichenfolge. Diese Zeile sieht so aus:
[Größe des gesamten Dokuments][Leerzeichen][Größe des aktuellen Blocks][Leerzeichen][Adresse des nächsten Blocks], wobei:
CRLF – Standard-Windows-Zeilenvorschub, Zeichenpaar rn (0x0D,0x0A) Größe des gesamten Dokuments – die Gesamtlänge des Dokuments in Bytes. Geschrieben als Zeichenfolgendarstellung einer Hexadezimalzahl. Länge - 8 Bytes. Raum – Raum. Zeichen 0x20 Die Größe des aktuellen Blocks ist die Länge des Blockkörpers in Bytes. Es wird auch als Zeichenfolgendarstellung einer INT32-Zahl im Hexadezimalformat geschrieben. Wenn ein Dokument aus einem einzelnen Block besteht, ist die Größe des gesamten Dokuments entweder kleiner oder gleich der Größe des aktuellen Blocks (was logisch ist). Die Adresse des nächsten Blocks ist die Adresse, an der sich der nächste Block befindet Dokument befindet. Wenn die Adresse des nächsten Blocks INT_MAX ist, bedeutet dies, dass es keinen nächsten Block gibt. Die Adresse des nächsten Blocks wird ebenfalls als String-Darstellung der Nummer geschrieben.
Unmittelbar nach dem Blockkopf folgt der Blockkörper, der die im Feld „Aktuelle Blockgröße“ angegebene Länge hat.
Schauen wir uns das Bild an: Die Länge des gesamten Dokuments beträgt 0x54 Bytes, diese 0x54 Bytes sind mit einem roten Rahmen hervorgehoben. Hierbei handelt es sich um Dokumentdaten. Die Blocklänge beträgt 0x200 Bytes, d.h. länger als die Länge des Dokuments selbst. Aus diesem Grund stellen die verbleibenden Daten im Block „Nullen“ ungenutzten Speicherplatzes dar. Signifikante Bytes sind diejenigen, die mit einem roten Rand gekennzeichnet sind.
Wenn die Länge des Dokuments größer als die Länge des Blocks ist, muss der nächste Block gelesen werden. Wenn im Feld „Nächste Blockadresse“ ein anderer Wert als 0x7fffffff steht, müssen Sie den aktuellen Block lesen, dann zu dieser Adresse gehen und einen anderen Block lesen. Wenn dieser Block auch die Adresse des nächsten Blocks enthält, müssen Sie auch dorthin gehen. Dadurch entsteht eine „Kette“ von Blöcken, aus denen das Dokument besteht.
Das Lesen muss fortgesetzt werden, bis im Feld „Adresse des nächsten Blocks“ der Wert 0x7fffffff gefunden wird oder bis die im Feld „Größe des gesamten Dokuments“ angegebene Anzahl an Bytes gelesen ist.
Das Feld „Gesamte Dokumentgröße“ ist nur für den ersten Block von Bedeutung. In allen nachfolgenden Blöcken des Dokuments hat es den Wert 0x00000000.
Container-Header-Format
Der Container-Header ist 16 Byte lang und besteht aus folgenden Feldern:
|
Erläuterung |
||
|
Adresse des ersten freien Blocks |
INT32 (4 Bytes) |
Der Offset, bei dem die Kette freier Blöcke beginnt |
|
Standardblockgröße |
INT32 (4 Bytes) |
Ein Block kann eine beliebige Länge haben, die Standardlänge kann jedoch beispielsweise zum Hinzufügen neuer Blöcke verwendet werden. |
|
Feld mit unbekanntem Zweck (siehe Kommentare zum Artikel) Stimmt oft mit der Anzahl der Dateien im Container überein |
INT32 (4 Bytes) |
Eine Zahl, die einen bestimmten Wert widerspiegelt, der normalerweise mit der Anzahl der Dateien im Container übereinstimmt. Kollegen in den Kommentaren glauben jedoch, dass dies nicht ganz stimmt. Diese Zahl hat keinerlei Einfluss auf den Containerinterpretationsalgorithmus; sie kann ignoriert werden. |
|
Reserviertes Feld |
INT32 (4 Bytes) |
Immer gleich 0 (ist es immer?) |
Das Attributdokument beschreibt den Dateinamen und das Datum, an dem es erstellt/geändert wurde.
|
Erläuterung |
||
|
Dateierstellungszeit |
UINT64 (8 Bytes) |
Dateierstellungszeit, ausgedrückt in 100-Mikrosekunden-Intervallen seit Beginn unserer Ära (01.01.0001 00:00:00) |
|
Dateiänderungszeit |
UINT64 (8 Bytes) |
Ebenfalls |
|
Reserviertes Feld |
INT32 (4 Bytes) |
Immer 0. Möglicherweise handelt es sich hierbei um Attributflags, etwa schreibgeschützt, ausgeblendet usw. Ich habe jedoch keine Dateien gefunden, bei denen dieses Feld von Null abweicht. |
|
Dateiname |
Zeichenfolge im UTF-16-Format |
Belegt den gesamten verbleibenden Textkörper des Dokuments (abzüglich 2 Datumsangaben und einem Reservefeld) |
Ein Inhaltsverzeichnis lesen. Ein Inhaltsverzeichnisdokument aus Blöcken zusammenstellen und lesen. Alle Einträge im Inhaltsverzeichnisdokument durchlaufen und Attributdokumente (Namen) von Containerdateien lesen. Jeden empfangenen Namen mit der Adresse eines Inhaltsdokuments abgleichen. Die Ausgabe ist a Korrespondenz „Dateiname“ -> „Inhaltsadresse“ Dateien lesen. Nach Dateinamen die Adresse des Inhaltsdokuments aus dem Inhaltsverzeichnis abrufen. Inhaltsdokument aus Blöcken zusammensetzen. Wenn dies der Stammcontainer ist, entpacken Sie das Inhaltsdokument (es ist …). komprimiert) Fertig. Das resultierende Ergebnis sind die Daten der durchsuchten Datei. Update vom 25.02.2014
Abschließend
Dieser Artikel ist nicht die ultimative Wahrheit; er enthält wahrscheinlich sogar Fehler. Wenn dieses Thema für Sie jedoch interessant ist, dann hoffe ich, dass dieser Artikel Ihnen bei der Umsetzung Ihrer Projekte hilft. Viel Glück!
Wir haben oben erwähnt, dass die Konfiguration aus einer Datei mit der Erweiterung .CF importiert werden kann. Beispielsweise kann Ihnen ein befreundetes Unternehmen eine solche Datei zur Verfügung stellen, damit Sie die neueste Version der Konfiguration installieren und damit experimentieren können. Bei einer solchen Entwicklung der Ereignisse müssen Sie wie folgt vorgehen.
Zunächst sollten Sie in dem Ihnen bereits bekannten Fenster, das nach dem Start des Programms erscheint (Abb. 1.1), auf die Schaltfläche klicken Hinzufügen.
Wählen Sie im nächsten Fenster aus Schaffung einer neuen Informationsbasis.
Im nächsten Fenster müssen Sie den Punkt „Infobase ohne Konfiguration erstellen“ auswählen, um eine neue Konfiguration zu entwickeln oder eine zuvor entladene Infobase zu laden.
Geben Sie im nächsten Fenster den Namen der Datenbank an.
Nach Abschluss der in der Liste aufgeführten Aktionen Informationsbasen Es erscheint eine neue leere Datenbank. Jetzt müssen Sie es auswählen und auf die Schaltfläche Konfigurator klicken. Es öffnet sich das Konfiguratorfenster (Abb. 1.8).
Wenn Sie das Fenster zum ersten Mal öffnen, ist es leer und jetzt müssen wir einige Schritte ausführen, um die CF-Datei, die Sie haben, in die leere Konfiguration zu laden.
Menübefehl ausführen Konfiguration > Konfiguration öffnen. Das Programmfenster ändert sich – im linken Teil öffnet sich der Konfigurationsbaum. Es interessiert uns noch nicht. Jetzt können Sie den Befehl ausführen Konfiguration > Konfiguration aus Datei laden. Mit diesem Befehl können Sie die vorhandene (in unserem Fall leere) Konfiguration vollständig durch die in der CF-Datei gespeicherte Konfiguration ersetzen. Im erscheinenden Fenster, Abb. 1.9 müssen Sie den Pfad zu der Datei angeben, in der die Konfiguration, die Sie laden möchten, gespeichert ist.
Jetzt müssen Sie nur noch einen Knopf drücken Offen und warten Sie, bis das Programm die Konfiguration lädt. Dies kann recht lange dauern. Wenn das System Ihnen Fragen stellt (insbesondere zum Aktualisieren der Datenbankkonfiguration, zum Akzeptieren von Änderungen in der Struktur der Konfigurationsinformationen), beantworten Sie diese mit Ja.
In der unteren linken Ecke des Programmfensters werden Servicemeldungen über den Fortschritt des Konfigurationsupdates angezeigt. Nachdem das Update abgeschlossen ist (Dienstmeldungen zum Laden der Datenbank werden gestoppt), können Sie das Konfiguratorfenster schließen und das Programm im Benutzermodus ausführen. Allerdings ist in der Praxis die Installation Informationsbasis Die Verwendung einer der oben genannten Methoden schränkt in der Regel nicht die Dinge ein, die vor der ersten Ausführung der Konfiguration erledigt werden müssen. Insbesondere dürfen wir Updates nicht vergessen.
1.5. Konfigurationsaktualisierung
In der Praxis besteht nach der Installation der Konfiguration meist die Notwendigkeit, diese zu aktualisieren. Updates werden als Dateien mit der Erweiterung .CFU verteilt. Eine solche Datei wird bei der Update-Installation in einen Ordner kopiert, der entsprechend den Programmeinstellungen Konfigurations- und Update-Vorlagendateien enthält. In den allermeisten Fällen ist dies beispielsweise der Ordner C:\Programme\1cv81\tmplts\1c.
Wenn Sie über eine Koverfügen, sollten Sie prüfen, ob diese Ihre Konfiguration aktualisieren kann. Normalerweise finden Sie in den Dateien, die den Updates beiliegen, detaillierte Informationen darüber, welche Konfigurationsversionen aktualisiert werden sollen.
Bevor Sie die Konfiguration aktualisieren, müssen Sie eine Sicherungskopie Ihrer erstellen Informationsbasis. Wenn Sie ein neu erstelltes aktualisieren Informationsbasis Sie können auf diesen Schritt verzichten. Um sich jedoch vor den negativen Folgen möglicher Fehler beim Aktualisieren einer „Live“-Datenbank zu schützen, erstellen Sie am besten eine Sicherungskopie. Dazu können Sie verschiedene Techniken nutzen. Insbesondere bei Verwendung der Dateioption Informationsbasis Sie können einfach den Ordner mit dem Inhalt kopieren Informationsbasis. Sie können den Konfigurator mit der gewünschten Datenbank öffnen und den Befehl ausführen Verwaltung > Infobase herunterladen. Daten hochladen Informationsbasis haben die Erweiterung .DT. Herunterladen Informationsbasis, können Sie den Befehl verwenden Verwaltung > Infobase laden.
Um die Konfiguration zu aktualisieren, müssen Sie sie im Konfiguratormodus öffnen und dann die folgende Abfolge von Aktionen ausführen.
Wenn du. .. hast Informationsbasis Mit einer für Sie passenden Konfiguration können Sie 1C:Enterprise starten, im Startfenster die gewünschte Datenbank auswählen und auf die Schaltfläche 1C:Enterprise klicken. Normalerweise dauert der erste Start eines Programms mit einer neuen Konfiguration einige Zeit – das System führt vorbereitende Maßnahmen durch. Lassen Sie uns in der Zwischenzeit, während all diese Aktionen stattfinden, einige Bestimmungen zu den Funktionen des 1C: Accounting-Geräts besprechen.
1.6. Grundlegende Konfigurationsobjekte aus Sicht des Benutzers
1C:Accounting ist ein System zur Eingabe, Speicherung und Verarbeitung von Buchhaltungsdaten. Zu diesem Zweck verfügt es über eine Reihe von Komponenten ( Konfigurationsobjekte), mit denen Sie alle erforderlichen Vorgänge ausführen können. Das Hauptobjekt, das Sie beim Arbeiten im Programm verwenden müssen, heißt aufgerufen Dokumentieren. Mit Hilfe von Dokumenten gelangen Daten in das System. Dokumente werden von Benutzern ausgefüllt, beim Speichern werden Vorgänge zur Eingabe der Daten dieser Dokumente in das System ausgeführt und auf der Grundlage dieser Daten werden alle anderen Buchhaltungsvorgänge durchgeführt.
Wir können sagen, dass 1C: Accounting die Führung von Aufzeichnungen „aus dem Dokument“ vorsieht, was im Allgemeinen ziemlich logisch ist. Dokumente im 1C:Accounting-System sind den Dokumenten, mit denen sich jeder Buchhalter befassen muss, sehr ähnlich. Wir können sagen, dass es sich um elektronische Analoga gewöhnlicher Dokumente handelt. Bei Bedarf können Dokumente (bzw. deren gedruckte Formulare) auf einem Drucker ausgedruckt werden. Ein Objekt Dokumentenprotokoll Wird zum Gruppieren ähnlicher Dokumente verwendet und führt ähnliche Funktionen wie ein Ordner aus, in dem gewöhnliche Papierdokumente gespeichert werden.
Jede Buchhaltungsabteilung beschäftigt sich nicht nur mit Dokumenten. Wie Sie wissen, Dokumente, oder wie sie in der Buchhaltungspraxis üblicherweise genannt werden – primäre Buchhaltungsunterlagen(oder auch nur „primär“) ist lediglich eine Quelle für Buchhaltungsinformationen. Die automatisierte Buchhaltung ist keine Ausnahme. Nachdem das Dokument in das System eingegeben wurde, generiert es Bewegungen gemäß Registern. Dieser für Anfänger recht komplizierte Satz bedeutet eigentlich nur, dass Daten aus Dokumenten (die normalerweise auf eine bestimmte Weise verarbeitet werden) in speziellen Tabellen, sogenannten Registern, aufgezeichnet werden. Es gibt verschiedene Arten von Registern.
Akkumulationsregister werden verwendet, um beliebige Informationen zu sammeln, normalerweise in numerischer Form. Zum Beispiel, um Daten über den Wareneingang im Lager und den Warenausgang zu speichern, mit der Möglichkeit, Salden und Umsätze abzurufen.
Informationsregister kann zum Speichern von Informationen verwendet werden, die sich im Laufe der Zeit ändern. Beispielsweise ist es in einem solchen Register durchaus möglich, den Preis der von Lieferanten erhaltenen Waren zu erfassen, um deren Wertänderungen im Zeitverlauf zu analysieren.
Buchhaltungsregister für Buchhaltungszwecke konzipiert.
Berechnungsregister werden benötigt, um Abrechnungsvorgänge durchzuführen, beispielsweise um die Löhne für Mitarbeiter einer Organisation zu berechnen. In der Konfiguration Unternehmensbuchhaltung Berechnungsregister werden nicht verwendet, aber wenn Sie in Zukunft für die 1C:Enterprise-Plattform programmieren möchten, müssen Sie zumindest über deren Existenz Bescheid wissen.
Nicht nur Dokumente und Register dienen der Organisation der Buchhaltung. Lassen Sie uns einige weitere Systemobjekte auflisten, mit denen Sie sich befassen müssen.
Um Daten zu speichern, die sich sehr selten oder im Idealfall überhaupt nicht ändern, Konstanten. Beispielsweise kann eine Konstante die Konfigurationsversionsnummer und die Währung der regulierten Buchhaltung speichern.
Zum Speichern verschiedener Referenzinformationen verwenden sie Verzeichnisse. Somit können Verzeichnisse Informationen über die Mitarbeiter, Materialien und Waren, Auftragnehmer usw. der Organisation speichern.
Systemobjekte mit selbsterklärendem Namen Berichte Wird verwendet, um verschiedene Berichte zu erhalten. Und das sogenannte Behandlungen- um verschiedene Operationen mit Daten durchzuführen.
In den folgenden Vorlesungen werden wir uns mit den Details dieser Objekte befassen.
Schlussfolgerungen
In dieser Vorlesung haben wir uns einige allgemeine Merkmale des Systems angesehen 1C:Enterprise 8.1., sprach über die Plattform und Konfigurationen, betrachtete die Funktionen der Implementierung von 1C: Accounting aus der Sicht des Benutzers und bereitete sich auf die praktische Arbeit mit der Konfiguration vor, indem er eine neue erstellte Informationsbasis. Diese Vorlesung war Ihre erste Einführung in Systemobjekte. In der nächsten Vorlesung werden wir uns das System genauer ansehen.
In diesem Artikel werde ich Ihnen beibringen, wie Sie eine 1C-Konfigurations-CF-Datei erstellen. Was ist diese Datei und für welche Zwecke wird sie benötigt? Beantworten wir die erste Frage: Die 1C-Konfiguration wird in dieser Datei gespeichert. Für welche Zwecke wird es am häufigsten verwendet? Um die gespeicherte Konfiguration in eine leere Datenbank zu laden. Aber es gibt noch eine weitere, nennen wir sie „nicht standardmäßige Anwendung“.
Mit der CF-Datei können Sie die 1C-Konfiguration aktualisieren. Mit dieser Datei können Sie mehrere Versionen gleichzeitig durchgehen, anstatt sie einzeln mithilfe von CFU-Dateien zu aktualisieren. Lesen Sie mehr über die schrittweise Aktualisierung der 1C-Konfiguration in meinem Artikel:
Und in diesem Artikel erfahren Sie, wie Sie eine CF-Datei erstellen. Dazu müssen Sie sich anmelden.
Bitte beachten Sie, dass der Benutzer, unter dem Sie sich am 1C-Datenbankkonfigurator anmelden, über Rechte zum Arbeiten mit dem Konfigurator verfügen muss.
Um eine CF-Datei zu erstellen, müssen Sie die Konfiguration öffnen, sofern diese geschlossen ist. Sehr oft kann es geschlossen werden. Um es zu öffnen, klicken Sie auf die Schaltfläche – Konfiguration öffnen.
Die Konfiguration hat sich geöffnet, links sehen Sie eine Liste der Metadaten.

Wenn Sie zum Konfigurator gegangen sind und links eine Liste mit Metadaten gesehen haben, bedeutet dies, dass die Konfiguration bereits geöffnet ist und Sie sie nicht öffnen müssen. Normalerweise ist im geöffneten Zustand die Schaltfläche „Konfiguration schließen“ aktiv

Wenn diese Schaltfläche aktiv ist, aber keine Liste mit Metadaten vorhanden ist, bedeutet dies, dass diese einfach nicht angezeigt werden.
Gehen Sie zum Konfigurationsmenü, in dem wir den Punkt „Konfiguration in Datei speichern“ auswählen.

Wir wählen das Verzeichnis aus, in dem wir es speichern möchten, und schreiben den Dateinamen. Normalerweise schreibe ich nach Konfigurationsname und Release-Nummer.

Alle Dateien werden gespeichert.
Jetzt können Sie mit seiner Hilfe ähnliche Konfigurationen aktualisieren.
Den Prozess der Erstellung einer CF-Datei können Sie im folgenden Video „live“ verfolgen:
Wie Sie die 1C-Konfiguration mithilfe einer CF-Datei aktualisieren, lesen Sie in meinem nächsten Artikel:
Lernen Sie die Grundlagen der Konfiguration in 1C und lernen Sie das Programmieren in „1C: Enterprise“ mithilfe meiner Bücher: und „Grundlagen der Entwicklung in 1C: Taxi“

Lernen Sie das Programmieren in 1C an Ort und Stelle aus meinem Buch „Programmieren in 1C in 11 Schritten“
- Das Buch ist in klarer und einfacher Sprache geschrieben – für einen Anfänger.
- Lernen Sie, die 1C-Architektur zu verstehen;
- Sie beginnen mit dem Schreiben von Code in der 1C-Sprache;
- Beherrschen Sie grundlegende Programmiertechniken;
- Festigen Sie Ihr Wissen mithilfe eines Problembuchs.

Ein ausgezeichneter Leitfaden zur Entwicklung in einer verwalteten 1C-Anwendung, sowohl für unerfahrene Entwickler als auch für erfahrene Programmierer.
- Sehr zugängliche und verständliche Präsentationssprache
- Das Buch wird per E-Mail im PDF-Format verschickt. Kann auf jedem Gerät geöffnet werden!
- Verstehen Sie die Ideologie einer verwalteten 1C-Anwendung
- Erfahren Sie, wie Sie eine verwaltete Anwendung entwickeln.
- Lernen Sie, verwaltete 1C-Formulare zu entwickeln;
- Sie können mit den grundlegenden und notwendigen Elementen verwalteter Formulare arbeiten
- Das Programmieren unter einer verwalteten Anwendung wird klarer
Aktionscode für 15 % Rabatt - 48PVXHeYu
Wenn Ihnen diese Lektion bei der Lösung eines Problems geholfen hat, sie Ihnen gefallen hat oder Sie sie nützlich fanden, dann können Sie mein Projekt unterstützen, indem Sie einen beliebigen Betrag spenden:
Sie können manuell bezahlen:
Yandex.Money - 410012882996301
Webgeld – R955262494655
Treten Sie meinen Gruppen bei.
Wir hoffen, dass wir Ihnen bei der Lösung Ihres Problems mit der CF-Datei geholfen haben. Wenn Sie nicht wissen, wo Sie eine Anwendung aus unserer Liste herunterladen können, klicken Sie auf den Link (dies ist der Name des Programms). Dort finden Sie detailliertere Informationen darüber, wo Sie die sichere Installationsversion der erforderlichen Anwendung herunterladen können.
Ein Besuch dieser Seite soll Ihnen dabei helfen, diese oder ähnliche Fragen konkret zu beantworten:
- Wie öffne ich eine Datei mit der CF-Erweiterung?
- Wie konvertiert man eine CF-Datei in ein anderes Format?
- Was ist die Erweiterung des CF-Dateiformats?
- Welche Programme unterstützen die CF-Datei?
Wenn Sie nach Durchsicht der Materialien auf dieser Seite immer noch keine zufriedenstellende Antwort auf eine der oben gestellten Fragen erhalten haben, bedeutet dies, dass die hier bereitgestellten Informationen zur CF-Datei unvollständig sind. Kontaktieren Sie uns über das Kontaktformular und schreiben Sie, welche Informationen Sie nicht gefunden haben.
Was könnte sonst noch Probleme verursachen?
Es kann mehrere Gründe geben, warum Sie eine CF-Datei nicht öffnen können (nicht nur das Fehlen einer entsprechenden Anwendung).
Erstens- Die CF-Datei ist möglicherweise falsch (inkompatibel) mit der installierten Anwendung verknüpft, um sie zu unterstützen. In diesem Fall müssen Sie diese Verbindung selbst ändern. Klicken Sie dazu mit der rechten Maustaste auf die CF-Datei, die Sie bearbeiten möchten, und klicken Sie auf die Option „Zum Öffnen mit“ und wählen Sie dann das von Ihnen installierte Programm aus der Liste aus. Nach dieser Aktion sollten die Probleme beim Öffnen der CF-Datei vollständig verschwinden.
Zweitens- Die Datei, die Sie öffnen möchten, ist möglicherweise einfach beschädigt. In diesem Fall wäre es am besten, eine neue Version davon zu finden oder sie erneut von derselben Quelle herunterzuladen (vielleicht wurde der Download der CF-Datei in der vorherigen Sitzung aus irgendeinem Grund nicht abgeschlossen und sie konnte nicht korrekt geöffnet werden). .
Möchtest du helfen?
Wenn Sie weitere Informationen zur CF-Dateierweiterung haben, wären wir Ihnen dankbar, wenn Sie diese mit den Benutzern unserer Website teilen. Nutzen Sie das untenstehende Formular und senden Sie uns Ihre Informationen zur CF-Datei.